This post is part of series – Posts 0 and 1
So before we go any further let’s submit our results to Kaggle and see where we stand after just a little bit of work. To create a submission we need to apply our model to the provided test set and submit a csv in the required format, in this case an ID column and the prediction for emissions.
In order to create our predictions we need to prepare our test set in the same way we did for training. Since we already filled the null values with the mean from the training set we can focus on applying our one hot encoding that we saved via pickle. The code below is a little overkill for applying a single encoder, but it will act as the backbone for being able to iterate through multiple encoders when we scale it up.
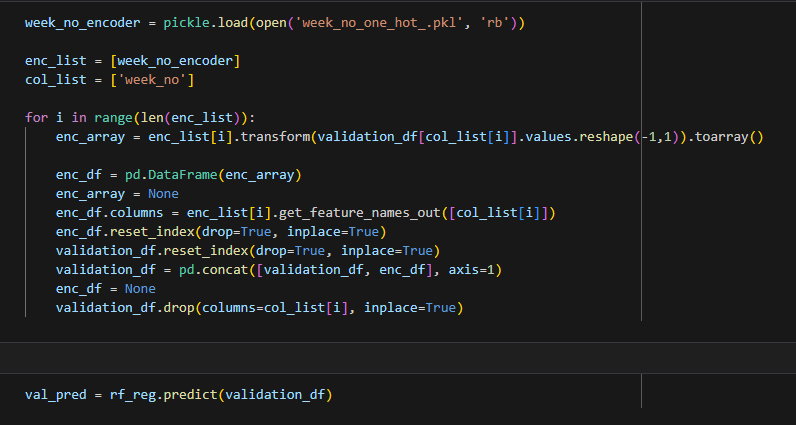
Now that we have an array of our predictions we just need to concatenate it with the ID field from the validation dataframe and create the submission. Once we have the csv it can submitted via the command line / terminal or through the Kaggle web interface.
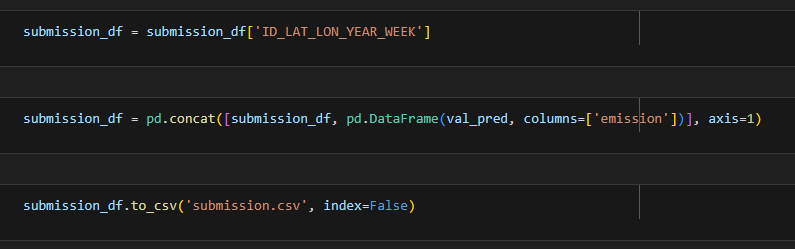
After submitting we find that we are 795 out of 1,138; so not last, but not in the top half either. Let’s see if we can improve.
Going back top imputation of missing values let’s trying using sklearn’s KNN imputer rather than a simple mean. The code below highlights how to initialize the imputer and prepare the data for imputation.
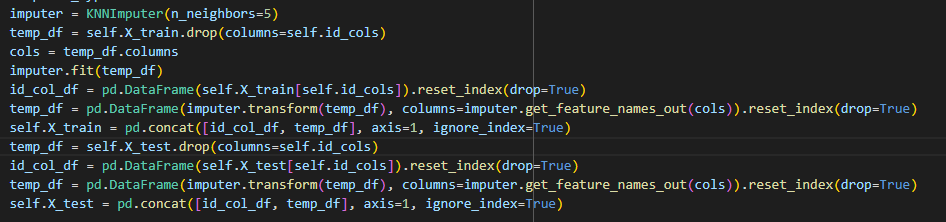
After running the KNN imputer and refitting the random forest our score goes from 45.5 to 45.2 which is technically an improvement, but not a huge one. Finally, let ‘s circle back to the columns which had a suspicious number of zeroes and see if using the KNN imputer on them helps resolve the issues. Those two columns were the formaldehyde and sulphur dioxide cloud fraction columns. Let’s replace the 0s in those columns with imputed values and see how that impacts our accuracy (see code below; sorry my syntax highlighting has been misbehaving).

After making that change, rerunning the KNN imputer, and refitting the random forest our submission score changes to 52.3 so not an improvement… Back to the drawing board…
